HTMLImporterプラグインは、URLを指定してHTMLからデータを移行する機能を提供します。 本文推定機能により、HTMLからコンテンツ部分(ナビゲーションやヘッダ・フッタ部を除く)を自動抽出してデータを移行するため、移行元のサイトがどのCMSで運用されているかを問わずにデータ移行できます。 metaタグのデータのインポート、ページに含まれている画像やダウンロード対象のリンクファイルをあわせてインポートできます。 また、URL指定ではなく、ローカルにHTMLや画像ファイルなどをZIPアーカイブ化してアップロードしてインポートする機能も提供します。
利用にあたっては、DataMigratorプラグインが有効である必要があります。
プラグインの利用
- システムのプラグインの管理画面で、HTMLImporter と DataMigrator 別ウィンドウで開きますにチェックを入れて有効化します。
利用方法
- HTMLインポートを行いたいスコープ(システムまたはスペース)の「ツール」メニューから「データ移行」を選択して画面遷移します。
- インポート対象モデル※を選択し、「フォーマット」ドロップダウンから「HTML」を選択します。
- オプション「ZIPファイル」「URL」のいずれかを選択します。
- 「ZIPファイル」を選択した場合、ファイルをアップロード、「URL」を選択した場合はテキストエリアに1行1URL形式でURLのリストを入力して「送信する」をクリックします。
- 取り込むポイントの指定などをしてから、「インポート開始」をクリックしてデータをインポートします。
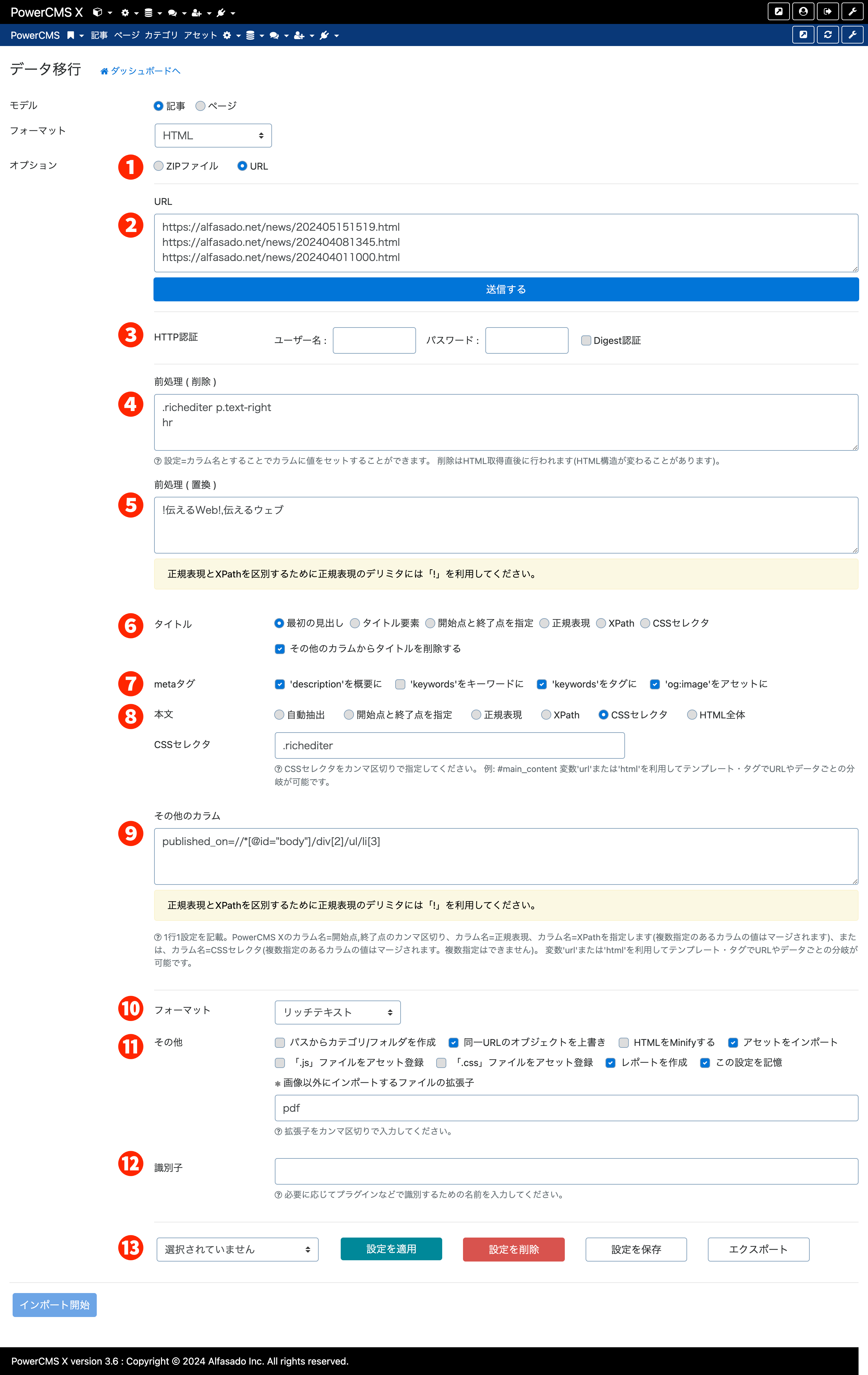
※ 記事・ページのほか、モデルの設定画面で「インポート&エクスポート」が選択されているモデルが選択できます。インポート権限と、対象モデルに対する新規作成の権限が必要です。
取り込みの設定
1. オプション
「ZIPファイル」「URL」のいずれかを選択します。
2. URL(またはファイル添付)
「ZIPファイル」を選択した場合、ファイルをアップロード、「URL」を選択した場合はテキストエリアに1行1URL形式でURLのリストを入力して「送信する」をクリックします。
3. HTTP認証
URLを指定してインポートする時、URLに対してBasic認証が設定されている時、IDとパスワードを入力します。
4. 前処理( 削除 )
処理開始前に削除したい要素を正規表現、XPathまたはCSSセレクタで1行1設定指定できます。 設定=カラム名とすることでカラムに値をセットすることができます。 削除はHTML取得直後に行われます(HTML構造が変わることがあります)。
5. 前処理 ( 置換 )
処理開始前に置換する箇所を正規表現、XPathまたはCSSセレクターと置換パターンまたは文字列の CSV形式で記述します。
6. タイトル(モデルによって表示される項目名は異なります)
タイトル要素 : HTMLの title要素を取り込みます。この時、セパレータを指定できます。
タイトルが「PowerCMS X Ver. 1.020リリースノート | PowerCMS X」の時、セパレータに「 | 」を指定すると、「PowerCMS X Ver. 1.020リリースノート」がタイトルとなります。
正規表現での指定例
/<h1[^>]*>\s*(.*?)\s*<\/h1\s*>/XPathでの指定例
h1タグ内を指定するときは、以下のように指定します。
//*/h1CSSセレクタでの指定例
<h1 class="contentTitle">タイトル</h1>を指定するには以下のようにします。
h1.contentTitle※ マッチしなかった場合は title要素が利用されます。
7.メタタグ(モデルによって表示される項目名は異なります)
- 'description'を概要に : meta description を概要欄にインポートします。
- 'keywords'をキーワードに : meta keywords をキーワード欄にインポートします。
- 'keywords'をタグに : meta keywords のカンマ区切り文字列をタグとしてインポートします。
- 'og:image'をアセットに : og:image をアセットとしてリレーション設定します。
8. 本文(モデルによって表示される項目名は異なります)
「自動抽出」「開始点と終了点を指定」「正規表現」「XPath」「CSSセレクタ」から選択します。
- 自動抽出 : 本文ブロックをHTMLから推定して取り込みを行います。
- 開始点と終了点を指定 : 以下の例では class="page-body"指定のある div要素の中身を取り込みます。
開始点と終了点の指定例
<div class="page-body">,</div>正規表現での指定例
取り込みたい部分を正規表現で指定します。抽出する範囲を括弧 (( ... )) でキャプチャしてください。
/<div class="page-body">\s*(.*?)\s*<\/div>/sXPathでの指定例
XPathを指定します。以下の例では class="page-body"指定のある div要素の中身を取り込みます。
//div[contains(@class, 'page-body')]CSSセレクタでの指定例
div.page-body正規表現や開始点・終了点の指定と異なり、XPath / CSSセレクタを指定した場合は、該当する要素が複数存在する場合に以下の値をマージして取り込みます。
9. その他のカラム
- 1行1設定を記載します。PowerCMS Xのカラム名=開始点,終了点のカンマ区切り、カラム名=正規表現※カラム名=XPath、もしくはCSSセレクタを指定します。
- XPath / CSSセレクタを指定した場合は、該当する要素が複数存在する場合に以下の値をマージして取り込みます。
- 正規表現とXPathを区別するために正規表現のデリミタには「!」を利用してください。
- フィールドについては「field.フィールドのベースネーム」としてください。
その他のカラムの指定例
excerpt=<meta name="description"content=",">
keywords=!<meta name="keywords" content="(.*?)">!
published_on=//*[contains(@class, 'date')]
subtitle=#subtitle
field.content=//*[contains(@class, 'content')]※ 日付型のカラムについては書式の調整を自動的に試みます。
バイナリ型カラムへの値のインポート
meta property="og:image"要素、a要素または img要素をXPathで指定することで、リンク先のファイルのデータをバイナリ型のカラムに取り込むことができます。 ※ 環境変数 denied_exts に指定のある拡張子のファイルは取り込まれません。
og_imageというバイナリ型カラムがある場合の指定例
og_image=//meta[contains(@property, 'og:image')]10. フォーマット
記事/ページ/ウィジェットなどの、リッチテキスト欄があり、text_formatカラムのあるモデルで選択できます。
11. その他
- パスからカテゴリ/フォルダを作成 : 記事/ページで選択できます。ディレクトリのパスからカテゴリ/フォルダを作成し、インポートしたオブジェクトを関連付けます。
- 同一URLのオブジェクトを上書き : 既にインポートした同一URLまたはパスのオブジェクトがあった場合、新規にオブジェクトを生成せず、既存のオブジェクトを上書きします。
- HTMLをMinifyする : リッチテキスト欄やテキストエリア型のカラムへの値のインポート時にHTMLをMinify(コード圧縮)します。
- アセットをインポート : モデルに「アセット」チェックのあるモデルで選択できます。インポートするテキスト中の img要素やその他の要素をアセットとして取り込み、オブジェクトと関連付けます。
- 「.js」ファイルをアセット登録 : script要素の src属性に指定された拡張子「.js」のファイルをアセットに取り込んで関連づけます。
- 「.css」ファイルをアセット登録 : link要素の href属性に指定された拡張子「.css」のファイルをアセットに取り込んで関連づけます。
- レポートを作成 : チェックを入れると完了後の画面に[ レポートをエクスポートする ]リンクが表示されます。リンクをクリックすると CSVファイルをエクスポートすることができます。環境変数「html_importer_report_encoding」に「Shift_JIS」を指定することで CSVの文字コードを変更できます。
- この設定を記憶 : 「インポート開始」をクリックした時に設定をクッキーに保存します。
- 画像以外にインポートするファイルの拡張子 : 「アセットをインポート」にチェックを入れた時、インポートするテキスト中に指定した拡張子のファイルへのリンク(a要素)が存在する時、アセットとして取り込み、オブジェクトと関連付けます※。
※ 環境変数 denied_exts に指定のある拡張子のファイルは取り込まれません。
12. 識別子
必要に応じてプラグインなどで識別するための名前を入力します。入力した値は「$app->param('html_identifier')」で取得できます。
13. 設定の保存・呼び出し・エクスポート
モデルごとに取り込み設定を保存できます。保存された設定はインポート画面下部のドロップダウンメニューから選択できます。
- 設定を適用 : ドロップダウンで選択した設定を適用します。
- 設定を削除 : ドロップダウンで選択した設定を削除します。
- 設定を保存 : 現在の設定に名前を付けて保存します。
デフォルトでは、設定はモデルごとに保存されます。以下の環境変数の指定でスコープやユーザーごとに設定を保存することができます。
- htmlimporter_setting_by_scope : 設定をシステム・スペースなどのスコープ毎に保存し、再利用できます。初期値は falseです。
- htmlimporter_setting_by_user : 設定をシステム・スペースなどのユーザー毎に保存し、再利用できます。初期値は falseです。
YAML形式のファイルにエクスポートできます。
- 環境変数「htmlimporter_settings_paths」にyamlファイルを設置するディレクトリの配列を指定して、そこにファイルを設置します。または、HTMLImporterプラグイン配下「settings」フォルダに設置しても構いません。
- HTMLImporterプラグインを無効化して、再度有効化すると、設定が取り込まれます。
- 同じモデルに同名の設定がある時は、取り込みはスキップされます。
入力欄でのMTタグの利用について
各入力欄には MTタグを指定可能です。変数「url」に取り込み中のURL、変数「html」に取得したHTMLデータがセットされていますので、特定のURLの場合のみ設定を分岐するなどの設定が可能です。
プラグインによる処理の追加
該当のモデルに対する post_importコールバックに対応するプラグインを書くことで、インポート後のオブジェクトに対する後処理を追加できます。 第一引数 $cb からインポートタイプ、URLや HTMLソースなどを取得できます。
function post_import_entry ( $cb, $app, $obj, $original ) {
$format = isset( $cb['format'] ) ? $cb['format'] : '';
// html, movabletype, wordpress or noren.
if ( $format != 'html' ) {
return true;
}
$html = isset( $cb['data'] ) ? $cb['data'] : '';
// Do something.
return $obj->save();
}